

ChatGPT no busca lo que el usuario escribe. Busca esto.
Cómo ver exactamente qué contenido extraen ChatGPT, Perplexity y Google AI Overviews

Cuando preguntas a ChatGPT “¿cuál es el mejor CRM para startups?”, el modelo no envía esa frase a Bing.
La reescribe. La trocea. La convierte en tres o cuatro queries que tú nunca escribiste pero que determinan si tu contenido aparece o no en la respuesta.
Esto se llama query fan-out. Y hasta hace poco, era invisible.
Ya no.
Hoy te enseño a abrir los logs de red de tu navegador y ver exactamente qué queries genera ChatGPT, qué fragmentos extrae de cada página, y qué metadatos evalúa antes de decidir a quién cita.
Durante dos décadas, el SEO fue un juego de probabilidades contra una caja negra. Sabíamos lo que entraba (keywords, backlinks) y veíamos lo que salía (rankings). Pero el mecanismo interno de Google permanecía opaco.
Con la llegada de ChatGPT Search, Perplexity y los AI Overviews, la industria asumió que la caja se volvería aún más hermética. La IA como oráculo inescrutable.
Tras semanas analizando los logs de red de estas plataformas parta un cliente, he llegado a una conclusión diferente.
La caja puede que no esté tan cerrada.
El proceso de “razonamiento” de estos modelos es visiblemente rastreable en tu navegador. Y lo que revelan esos datos contradice gran parte de la sabiduría convencional sobre cómo optimizar contenido para la era de la IA.
No estamos tanto ante un problema de “calidad de contenido”. Estamos ante un problema de alineación sintáctica con la máquina.
(Nota: todas las técnicas y datos de este artículo están verificados con fuentes que enlazo a lo largo del texto. Si quieres comprobar algo, tienes los enlaces.)
La ilusión del prompt
El primer error conceptual es creer que ChatGPT busca lo que el usuario escribe.
No lo hace.
La realidad técnica, visible en los payloads JSON que se transmiten entre tu navegador y los servidores de OpenAI, revela un mecanismo mucho más sofisticado: el Query Fan-out.
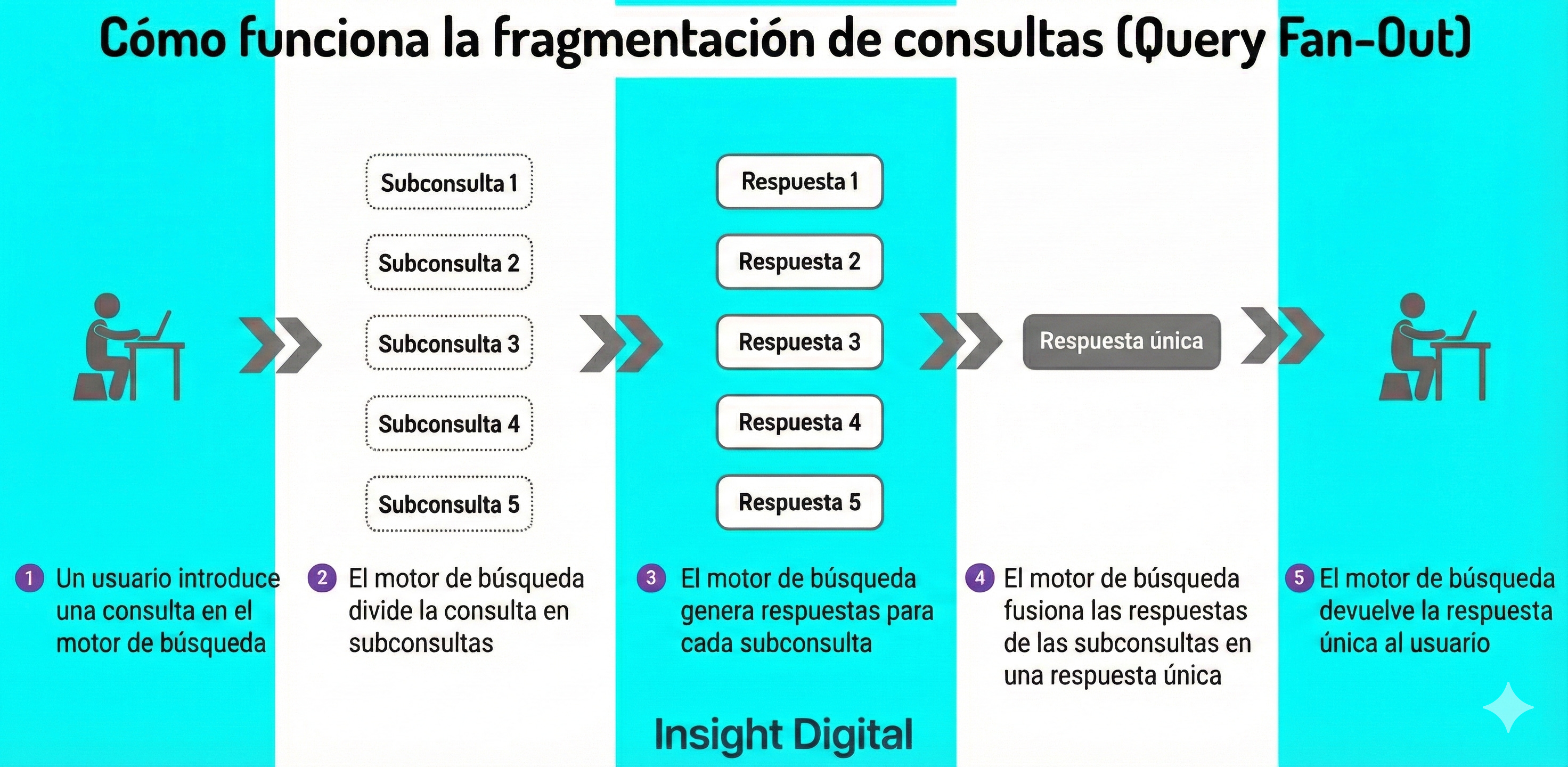
Cuando un usuario pregunta “¿cuál es el mejor CRM para una startup?”, el modelo no envía esa cadena a Bing. Actúa como alguien hiperactivo, descomponiendo la intención en múltiples vectores de búsqueda.
En los logs vemos que genera internamente:
“crm comparacion mejor 2025”“hubspot vs salesforce pymes”“mejor crm con gran volumen”
El usuario nunca escribió esas queries. La máquina las inventó.
La implicación estratégica es masiva: si tu contenido está optimizado para la pregunta del usuario, estás jugando al juego equivocado.
Para ser citado, debes optimizar para las queries intermedias que el modelo decide investigar. La visibilidad en esta nueva era depende de predecir y satisfacer esa reformulación interna.
Cómo ver las queries que la IA inventa
Todo esto está oculto en los logs de red de tu navegador (esto se lo dije así tal cual a mi cliente (es de Alimentación y Bebidas).
Y puedes acceder en menos de dos minutos.
(No es mío, esta técnica fue descubierta originalmente por David Konitzny y documentada por Practical Ecommerce. Lo que sigue es el proceso paso a paso.)
Abre ChatGPT y escribe tu consulta. Pulsa Enter.
Copia el ID del chat de la URL. Formato:
6925bce2-6858-832f-aff1-a972d36142bfClic derecho → “Inspeccionar” (o Ctrl+Shift+I / Cmd+Option+I)
Pestaña “Network”
Pega el ID del chat en la barra de búsqueda
Refresca la página
Verás dos entradas con el mismo ID. Haz clic en la del icono naranja.
Ya estás dentro.
Qué buscar (y por qué importa)
Una vez en el payload, usa Ctrl+F para buscar estos campos:
search_queries
Las queries exactas que ChatGPT genera a partir de tu prompt. Si preguntas sobre email marketing para ecommerce, el modelo puede generar:
“mejores herramientas para ecommerce 2025”
“klaviyo vs mailchimp ecommerce”
Esto te dice cómo la máquina interpreta las preguntas de tus usuarios. Si tu contenido no coincide con estas reformulaciones, no vas a ser citado.
snippets
Los fragmentos específicos que ChatGPT extrae de cada página. No la página completa. Solo lo que considera relevante para decidir si citar esa fuente.
Aquí descubres qué formatos se extraen realmente. Párrafos cortos y autocontenidos ganan. Bloques densos pierden.
title, url, description
Los metadatos que la IA ve antes de decidir. Si tu title tag es vago o tu meta description no resume el contenido, reduces tus probabilidades antes de que lean una sola palabra.
Bonus para ecommerce: p0, p1, p2
Cuando aparece un carrusel de productos, estos códigos mapean a bases de datos diferentes:
p0: Shopifyp1: Etsyp2: Índice interno de OpenAI
Si vendes productos y quieres aparecer en recomendaciones de ChatGPT, necesitas saber en qué índice deberías estar.
La economía de la citación
Si analizamos por qué ciertas fuentes dominan las respuestas de IA (Wikipedia, Reddit y propiedades de Google acaparan casi el 40% de las citaciones), la respuesta no es solo autoridad de dominio.
Es eficiencia computacional.
Al observar el campo snippets en los logs, descubrimos que los LLMs no “leen” artículos como un humano. Buscan fragmentos de texto que sean atómicos y autocontenidos.
Los datos de análisis de 36 millones de AI Overviews y 680 millones de citaciones lo confirman:
Plataforma Fuente #1 Fuente #2 Fuente #3 ChatGPT Wikipedia (47.9%) YouTube Reddit Google AI Overviews Reddit (21%) YouTube (18.8%) Quora (4%) Perplexity Reddit (46.7%) Wikipedia Dominios .ai

El modelo de selección favorece desproporcionadamente bloques de 40-60 palabras que comienzan con una respuesta directa y contienen un dato verificable.
Esto explica la Paradoja de Wikipedia: a pesar de perder 8% de tráfico humano en 2025 (confirmado por la propia Wikimedia Foundation), sigue siendo la fuente primaria porque su estructura enciclopédica es, en esencia, una base de datos de snippets perfectos.
La lección es brutal: la narrativa larga, el contexto elaborado, la prosa elegante, los pilares del “buen contenido” humano, son a menudo demasiado ruido para la máquina.
Un párrafo que requiere leer el anterior para entenderse es un párrafo que la IA descartará en su fase de re-ranking.
La unidad mínima de valor ya no es el artículo. Es el párrafo mínimo.
El pipeline de selección de Google
Google no publica su algoritmo de selección para AI Overviews. Pero tras analizar patrones en miles de queries, el proceso funciona aproximadamente así:
Etapa 1: Recuperación inicial Búsqueda híbrida con embeddings semánticos más keywords tradicionales.
Etapa 2: Ranking semántico Re-ranking según relevancia semántica. Páginas con estructura clara y terminología consistente tienen ventaja.
Etapa 3: Filtrado E-E-A-T Señales de experiencia, expertise, autoridad. Backlinks, menciones en fuentes autoritativas, credenciales de autor.
Etapa 4: Re-ranking LLM Gemini evalúa qué fuentes ofrecen mejor contexto para sintetizar. Aquí una página #8 con contenido excepcional puede superar a una página #1 con contenido genérico.
Lo crítico: Puedes rankear #1 en Google y no ser citado nunca en AI Overviews. El ranking orgánico pasa las etapas 1-2. Pero si tu contenido falla en contexto o señales E-E-A-T, quedas fuera.

La zona de “Reviewed” vs “Selected”
Perplexity ofrece la visión más transparente de este darwinismo digital.
Su interfaz distingue entre fuentes Selected (citadas en la respuesta) y Reviewed (analizadas pero descartadas). Esta distinción es visible en la interfaz y revela exactamente qué contenido pasa el corte de citación y cuál no.
La diferencia rara vez es la veracidad de la información.
Es cómo se estructura.
Cómo usar esto:
Busca queries relevantes para tu negocio en Perplexity
Observa quién aparece en Selected vs Reviewed
Compara el contenido de ambos grupos
La diferencia te dice exactamente qué le falta a tu contenido para pasar el corte.
Lo que mueve de Reviewed a Selected:
Respuesta directa en las primeras 2 oraciones
Datos con fuente verificable
Estructura H2/H3 clara
Fecha de actualización reciente (Perplexity pesa mucho la frescura)
Schema: reducir la fricción cognitiva del modelo
La confirmación de Fabrice Canel (Principal Product Manager de Microsoft Bing) en SMX Munich, marzo 2025, sobre la importancia del Schema Markup refuerza esta tesis.
Cita textual: “Schema Markup helps Microsoft’s LLMs understand content.”
Etiquetar contenido con FAQPage o Article no es una cuestión técnica menor. Es la forma de reducir la fricción cognitiva del modelo.
En un entorno donde el coste computacional importa, la IA prefiere la fuente que ya viene pre-digerida. Si obligas al modelo a inferir qué parte de tu texto es la respuesta y qué parte es contexto, pierdes contra la fuente que se lo entrega estructurado en JSON.
Los schemas que impactan:
FAQ Page: Crítico.
Los pares pregunta-respuesta son exactamente el formato que los LLMs necesitan.
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [{
“@type”: “Question”,
“name”: “¿Cuánto cuesta implementar un CRM?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “El coste de implementación varía entre €5,000 y €150,000 dependiendo del tamaño y complejidad. Soluciones SaaS como HubSpot empiezan desde €25/usuario/mes.”
}
}]
}
Article con autor verificable: Conecta contenido con credenciales reales.
How To: Para contenido tutorial, permite extracción estructurada de pasos.
Lo que NO funciona: Schema sin contenido que lo respalde.
Si tu FAQPage tiene preguntas que no aparecen visibles en la página, Google lo ignora.
Reddit: la fuente que no puedes ignorar
Reddit representa el 21% de citaciones en Google AI Overviews y el 46.7% en Perplexity. Es una mina (disclaimer: no tengo nada que ver con ellos). He trabajado el orgánico y el pago en Reddit y tiene muy buenos resultados en varias etapas del funnel.
Si no tienes presencia ahí, estás cediendo una de las mayores fuentes de citación a tus competidores.
Cómo construir presencia sin ser baneado:
Ratio 10:1: Por cada mención de marca, 8-10 aportes de valor sin auto-promoción
AMAs en subreddits relevantes: Las sesiones de preguntas construyen autoridad
Respuestas técnicas con profundidad: No respuestas genéricas
Nunca enlaces directos: Menciona expertise, deja que otros busquen
Una mención orgánica en Reddit puede equivaler a €10-30K en valor publicitario según análisis de visibilidad en IA.
Otras plataformas que las IAs citan frecuentemente:
YouTube (18.8% en Google AI Overviews)
Quora (4%)
Stack Overflow (tech)
El caso práctico: de la oscuridad a la citación
Antes del caso, los números que justifican por qué esto importa.
Seer Interactive analizó 3,119 queries en 42 organizaciones (25.1M impresiones orgánicas, junio 2024 - septiembre 2025):
CTR orgánico con AI Overviews: 0.61% (caída del 61% desde 1.76%)
CTR en queries SIN AI Overviews: 1.62% (caída del 41%)
CTR cuando eres citado en AI Overview: +35% vs no citado
CTR en paid cuando eres citado: +91% vs no citado
El tráfico perdido no vuelve. Los usuarios van a ChatGPT, Perplexity, o directamente a marcas de confianza antes de llegar a Google.
Ahora el caso.
Trabajamos con un cliente B2B en servicios profesionales. Su contenido era profundo, experto y totalmente invisible para AI Overviews.
En lugar de crear contenido nuevo, reestructuramos el existente basándonos estrictamente en los logs de ChatGPT.
El proceso:
Semanas 1-3: Identificamos las queries reformuladas (las que la máquina inventaba) mediante análisis de logs. Descubrimos que no coincidían con nuestros H2s.
Semanas 4-6: Reescribimos 25 páginas:
Primeras 50 palabras = respuesta
3-5 snippets citables por página
FAQPage schema en 15 páginas
Datos específicos con fuente en cada página
Semanas 7-9: Amplificación externa:
47 respuestas de valor en subreddits relevantes
3 artículos en medios sectoriales
El resultado no fue lineal.
En 90 días, pasaron de cero a 17 citaciones consistentes en queries de alto valor.
Lo fascinante no es solo el volumen. Es la conversión.
El tráfico referido por IA mostró una intención de solicitud de información-compra 3.2x superior al orgánico tradicional. Cuando la IA actúa como filtro de confianza, el usuario que hace clic ya está en la fase final del embudo.
De las 25 páginas optimizadas, solo 8 concentran el 91% de las citaciones. Las que funcionan tienen snippets que responden preguntas en menos de 50 palabras.
Tu checklist de implementación
Te doy algunas notas de cómo empezar esta semana:
☐ Haz 10 queries relevantes en ChatGPT con búsqueda web activada
☐ Extrae las search_queries y compáralas con tus H2s actuales
☐ Identifica tus 3 páginas más importantes
☐ Reescribe las primeras 50 palabras como respuesta directa
Próximas 2 semanas:
☐ Añade FAQPage schema a páginas con contenido Q&A
☐ Crea 3-5 snippets citables en cada página prioritaria
Mes siguiente:
☐ Establece tracking mensual: 30 queries en ChatGPT, Perplexity y Google
☐ Crea presencia en 2 subreddits relevantes
☐ Configura regex en GA4 para trackear referrers de IA:
.*chatgpt\.com.*|.*perplexity.*|.*gemini\.google\.com.*|.*copilot\.microsoft\.com.*
La bifurcación
Esto no para, la verdad… Estamos presenciando una división en la web.
Existe una web para humanos, rica en matices y narrativa. Y una web para máquinas, estructurada, atómica y directa.
La mayoría de las empresas siguen intentando ganar en la segunda con las reglas de la primera.
La ventaja competitiva hoy no reside en escribir más. Reside en entender la arquitectura de recuperación de información de estos modelos.
Y esa arquitectura, por ahora, está expuesta en los logs de tu navegador. Y, ya lo has intuido, en tu capacidad de generar Awareness y reputación.
Este análisis es contenido premium de INSIGHT Digital. Hoy lo dejo abierto. Si te resulta útil, los suscriptores premium reciben cada semana técnicas como esta, más los prompts exactos, plantillas de auditoría y acceso al archivo completo. El botón está abajo.